DLLM(拡散言語モデル)について色々調べてみた
導入
バイト先でLLMサービスの開発を行っているのですが、最近は就活で「LLM触ってます!」とか言っちゃうとガチ勢の質問が来たら困るなぁ…と内心ひやひやしている就活中のunimaguです。 使ってる技術はLLMといってもembeddingだからDLLMなんて知らんよ…というお気持ちではありますが、就活が一段落したので調べてまとめてみました。ちなみに自分が画像分野の人間なので拡散モデルという画像分野の技術から自然言語に発展した今回の例は面白いアイディアだという感じです。(まあ拡散モデルは普段触ってないけど…) 間違い等あるかもしれませんがご了承ください。
対象とする読者
他分野の機械学習への知見がある人(著者が画像分野の人間なので)
- 初学者向け
- ちょこっと詳しい方向け
DLLMとは
近年、大規模言語モデル(LLM)の分野で「拡散型言語モデル(Diffusion Language Model)」という新しいアプローチが注目を集めています。 これは、従来の主流であった「自己回帰モデル」が抱える課題を克服し、テキスト生成の新たな可能性を切り開く技術として期待されています。 以下ではDLLMの元になった画像生成における拡散モデルの解説とDLLMとの対応関係について記述します。
自己回帰モデルとは
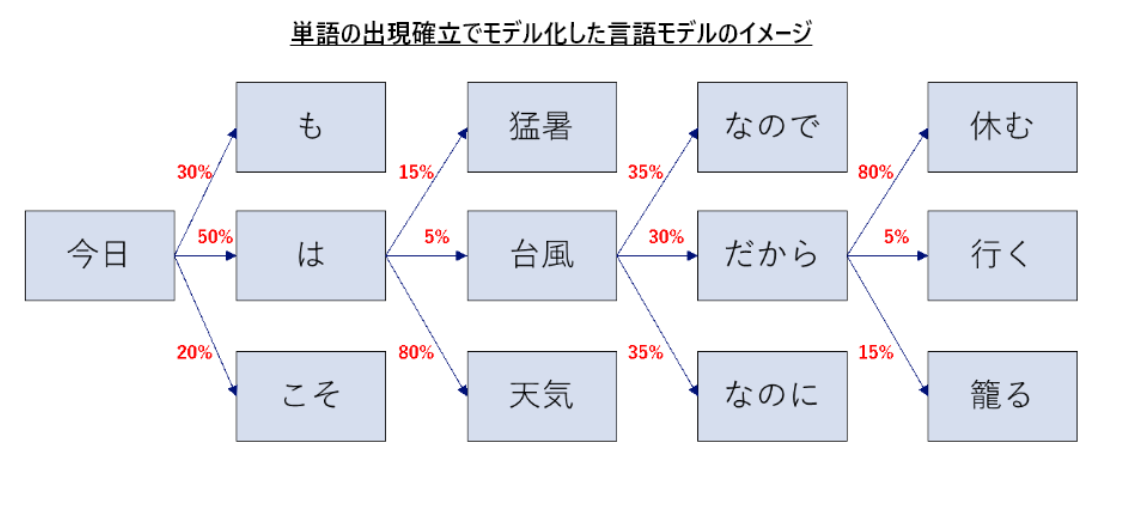
GPT,Claude等に代表される自然言語生成AIは基本的に「自己回帰モデル」と言われています。これは自己回帰モデルは、以下の図に示されるように左から右へ一単語ずつテキストを生成します。そのため、前のトークンが全て生成されないと次のトークンを生成できず、生成速度に限界がありました。
拡散モデルとは
拡散モデルは、もともと画像生成AIの分野で注目されていた技術です。(動画とか音声とかにも注目されていますね)Stable DiffusionやDALL-Eなどのサービスが代表的ですね。(ちょっと前にAIイラストレーターの界隈で物議を呼んでいましたね…)
仕組みは、大きく分けて次の2つのステップになります。
- 順方向拡散(Forward Diffusion):
- きれいな画像を用意します。
- 少しずつノイズ(砂嵐のようなもの)を加えていきます。
- 最終的には、完全にノイズだらけの状態にします。
- 逆方向拡散(Reverse Diffusion):
- 完全にノイズだらけの状態からスタートします。
- 少しずつノイズを取り除いていきます。
- 元のきれいな画像を復元します。
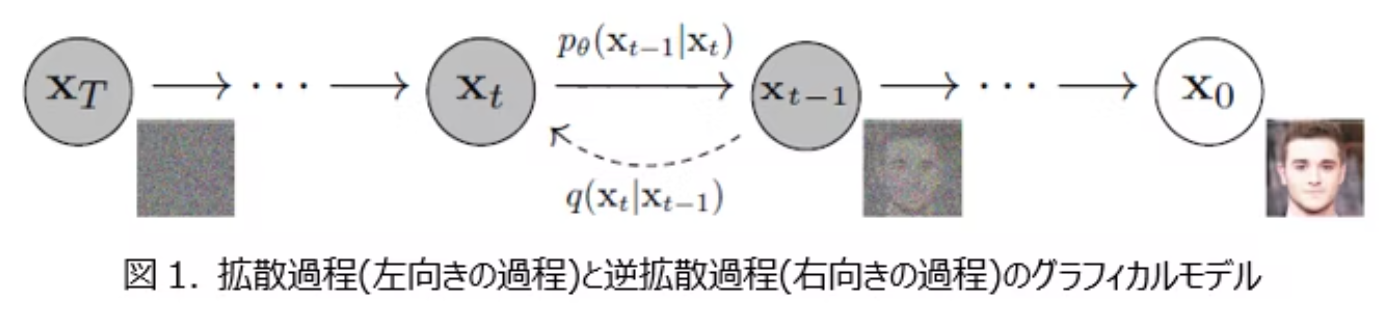
拡散過程はノイズを加えていくだけなので比較的に簡単な処理です。元の画像に対してガウシアンノイズ(標準正規分布に従うノイズ)を徐々に付加していく処理です。標準的な拡散モデルの手法では、この順拡散プロセスは確率的な定義に基づいたルールベースの結果が固定のただの計算処理なので機械学習は関与せず、学習前に作成する事が可能です。
逆方向拡散はノイズから画像を得るという生成モデルの主役となる処理で実際の機械学習が行われます。 各ステップで、モデルは現在のノイズの多い画像を入力として受け取り、そこから微量のノイズを予測し、それを除去(デノイジング)します この「ノイズ除去」のステップを複数回、反復的に繰り返すことで、画像は次第に鮮明になり、最終的に目的の画像が生成されます。 ノイズを除去することで入力データ本来の特徴を段階的に浮かび上がらせることで画像のパターンを学習します。(自転車の上に人がいる、皿の上に料理が盛られる,などの世界の汎用的な概念)元の鮮明な画像を段階的に再構築していく過程のため類似の画像を作成するのも強いです。最近ではこれの応用で動画生成の分野ではAIが考えたyoutuber動画が10分くらいで違和感少な目で50万再生位してて面白く作られててすごいなあという感じです。しかも生成するだけだから更新速度が高いし(ちなみに動画内容はコ〇ドットみたいなグループでなんかやる感じだった)
著者のお気持ち
- 指とか細部が乱れてたりすることが人とAIの見分け方だ!って言われてますね。ノイズを除去するタスク構造上、粒度的に難しいんだろうなというお気持ち
- あと常識的にあり得ない状況にも弱いんじゃないかな?例えばヤギは基本的に草原とか山岳にいて、そういう普遍的な概念を結びつけてそうだから海とか水中にヤギがいる画像を生成させようとしたら若干精度落ちるんじゃないかな?
DLLMとは
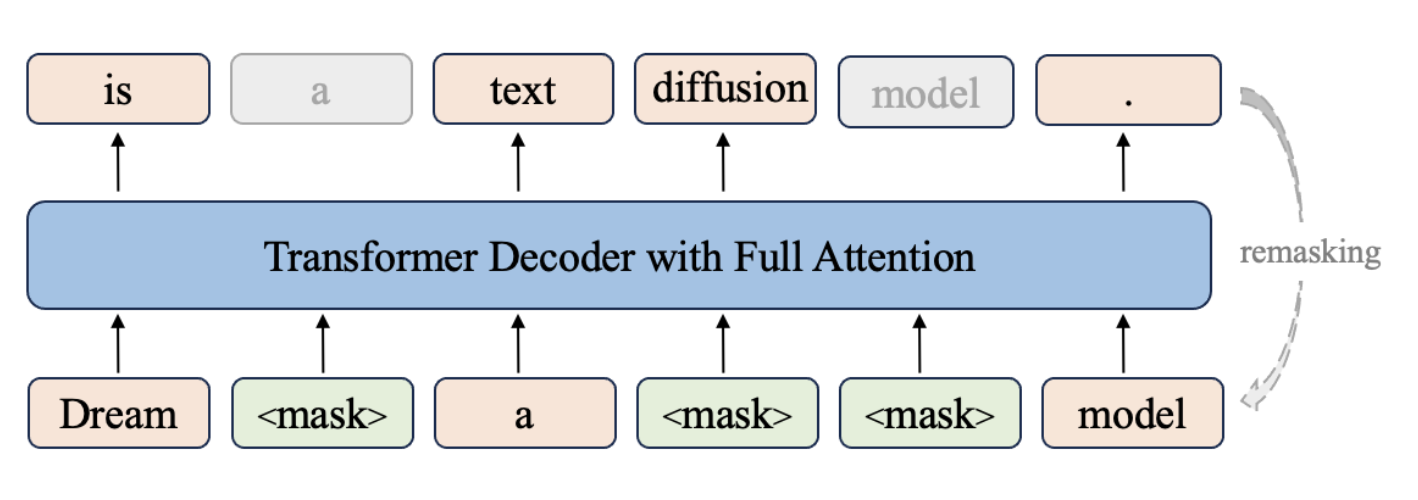
自己回帰モデルに対し、拡散型言語モデルは、画像生成AIで成功を収めた「拡散モデル」のアプローチをテキスト生成に応用した技術です。その基本的な仕組みは以下の通りです。
- 順方向拡散: 最初は無意味なトークン列や完全にマスクされた状態([MASK]のような特殊トークンに置き換え)から開始します。(画像生成でいうとこのノイズに該当)
- 逆方向拡散: その後、モデルはマスクされたトークンを予測し、元のテキストを少しずつ復元、最終的に意味の通る文章を完成させます
- 予測されたトークンのうち信頼度が低いものを再び[MASK]に戻し、次のステップで再度予測させる「remasking戦略」を用いることがあります。これにより、モデルは文章全体を見渡し、途中で生じた矛盾を解消しながら一貫性を保ち、誤りを修正できます
著者のお気持ち
- remasking戦略は人間が文章を下書きから推敲していくプロセスに似てるなあ。
- でも僕らが文章を考える方法はGPTとかで代表される自己回帰型だよね。これは一気に書くわけで生成方針でいうと人間の思考プロセスと違うなあ。
世界初の実用化サービス「Mercury」
公式サイトここで試せる!めっちゃ速い。
自己言及のパラドックスを試してみた。
 チューリングマシンよりは高級だね Ψ(∴)Ψ
チューリングマシンよりは高級だね Ψ(∴)Ψ
拡散言語モデルの利点
- 自己回帰モデルが一方向に進むのに対し、拡散モデルは文章全体を見渡しながら修正できるため、全体的な文章構造の整合性に優れると言われています
- 並列処理: 自己回帰モデルが1トークンずつ順次生成するのに対し、dLLMは全てのトークンを並列に処理できるため、同時に複数のトークンを出力し、生成を大幅に高速化できるらしいです
- 直感に反する推論: 数学問題などでは、答えが先に生成され、後からその思考過程が生成されるといった、自己回帰モデルでは起こりえない挙動が見られることもあります
拡散言語モデルの課題
- 従来のDLLM手法は並列化できてアルゴリズムはより高速であるにも関わらず、実は自己回帰型よりも推論速度が遅かったといわれています。それは自己回帰型には生成途中でKV‑cacheと言われる過去のトークンのK,Vをメモリに保存しておくことで新しく生成する際は新しいK,Vのみ追加計算する等の工夫をしたため速い生成を可能にしていました。(その分メモリ消費は激しいらしいですが)このキャッシュ戦略はDLLMのアルゴリズム上、単純には適応できなかったため登場当初は生成速度で劣っていたという経緯があります。(双方向(bidirectional)注意を用いる拡散モデルでは、あるトークンのKey/Valueはモデル内部の全コンテキストによって変化します。つまり、「過去トークン=固定」という扱いができず、標準的なARモデルでのKV‑cache利用法が通用しません)
(他にもCUDAのハードウェア最適化するコンパイルをすることでCPU→GPUへの通信を一回にまとめて通信オーバーヘッドの削減とか、トークンの工夫とか量子化とかいろんなことやってるんですね) また、DLLMの強みとされていた並列化も品質低下を引き起こすことが問題視されていました。
自己回帰型のKV‑cacheの様子(各トークンのK,Vがどのように保存・利用されているかを示しています)
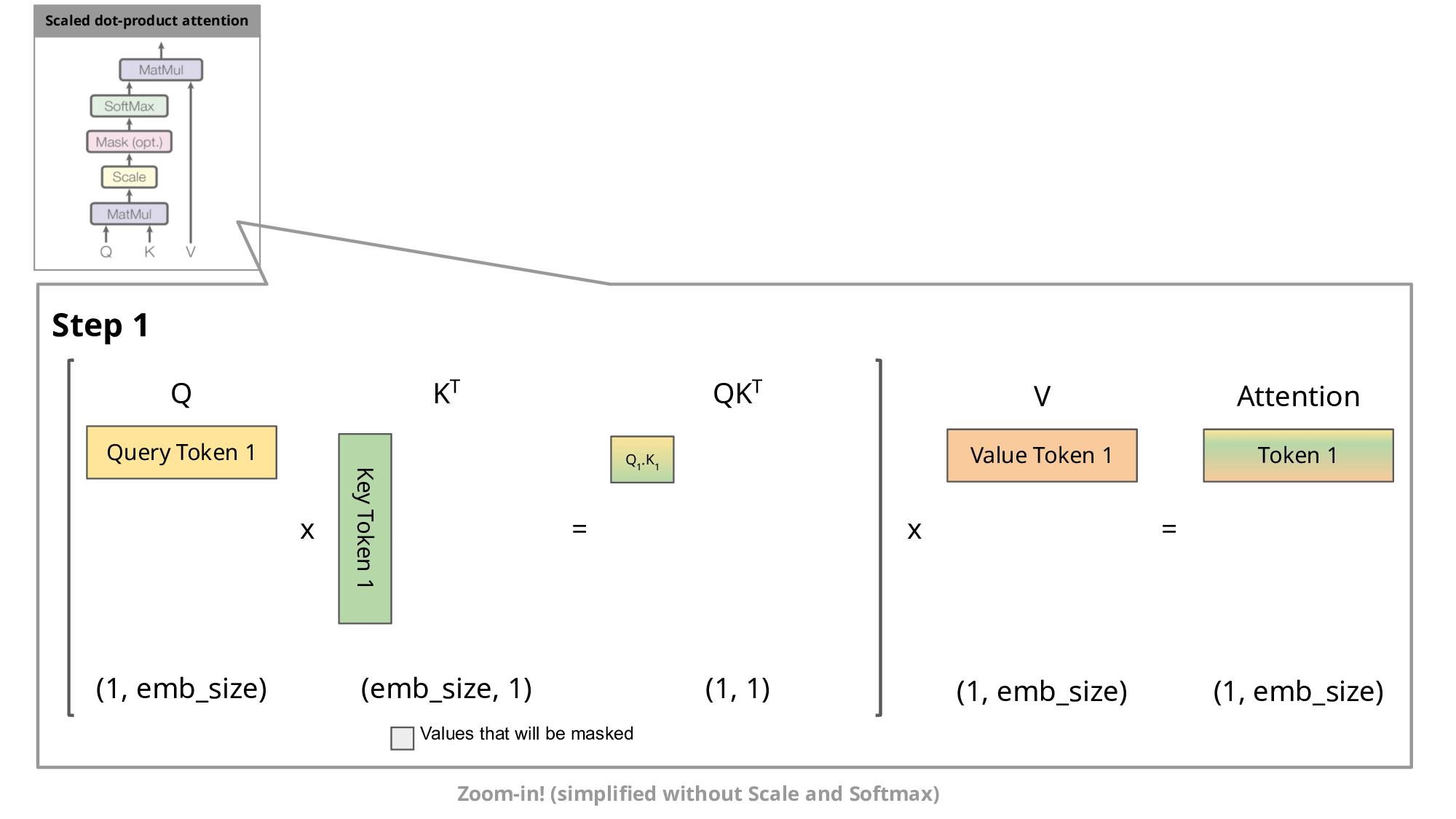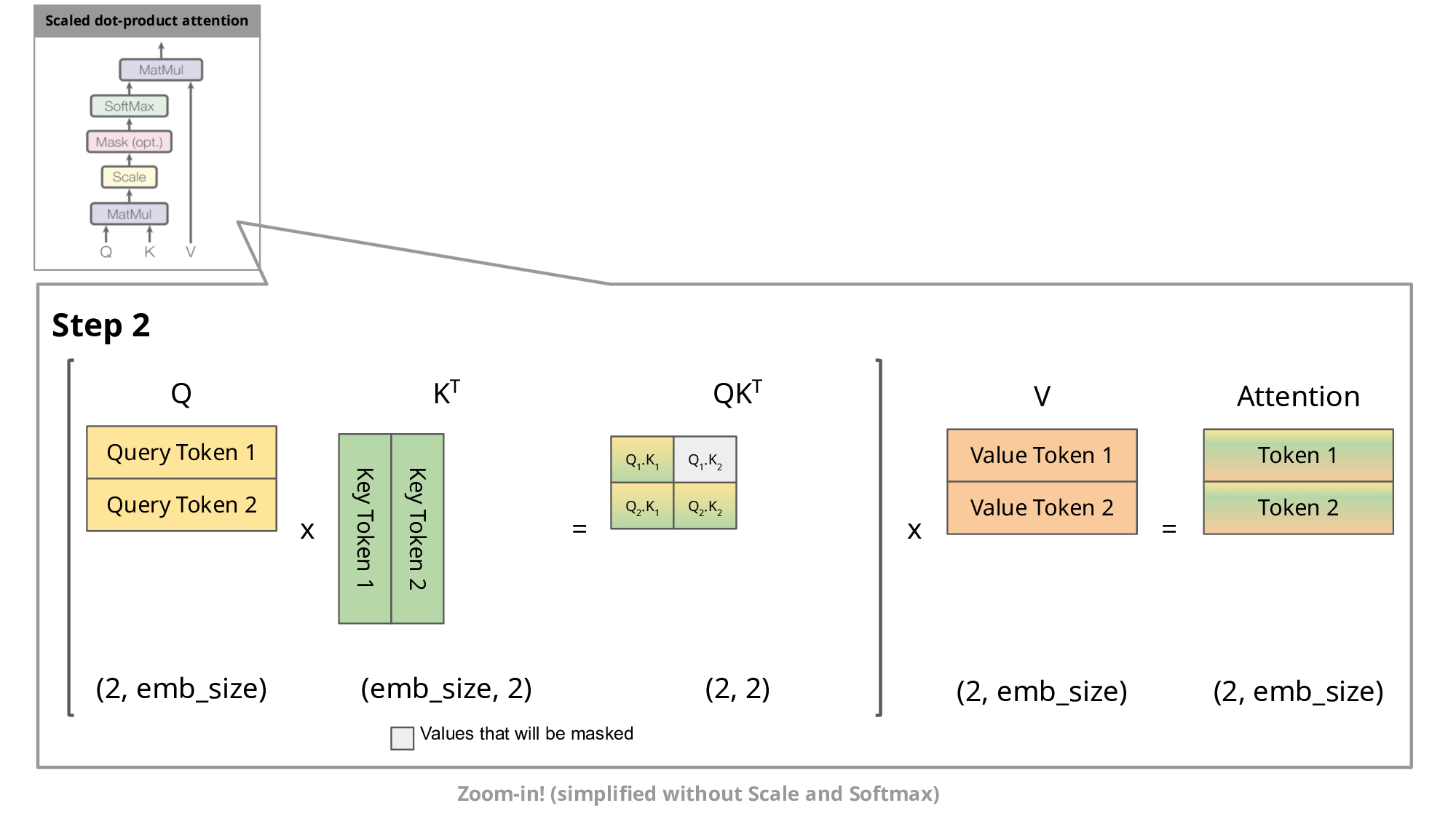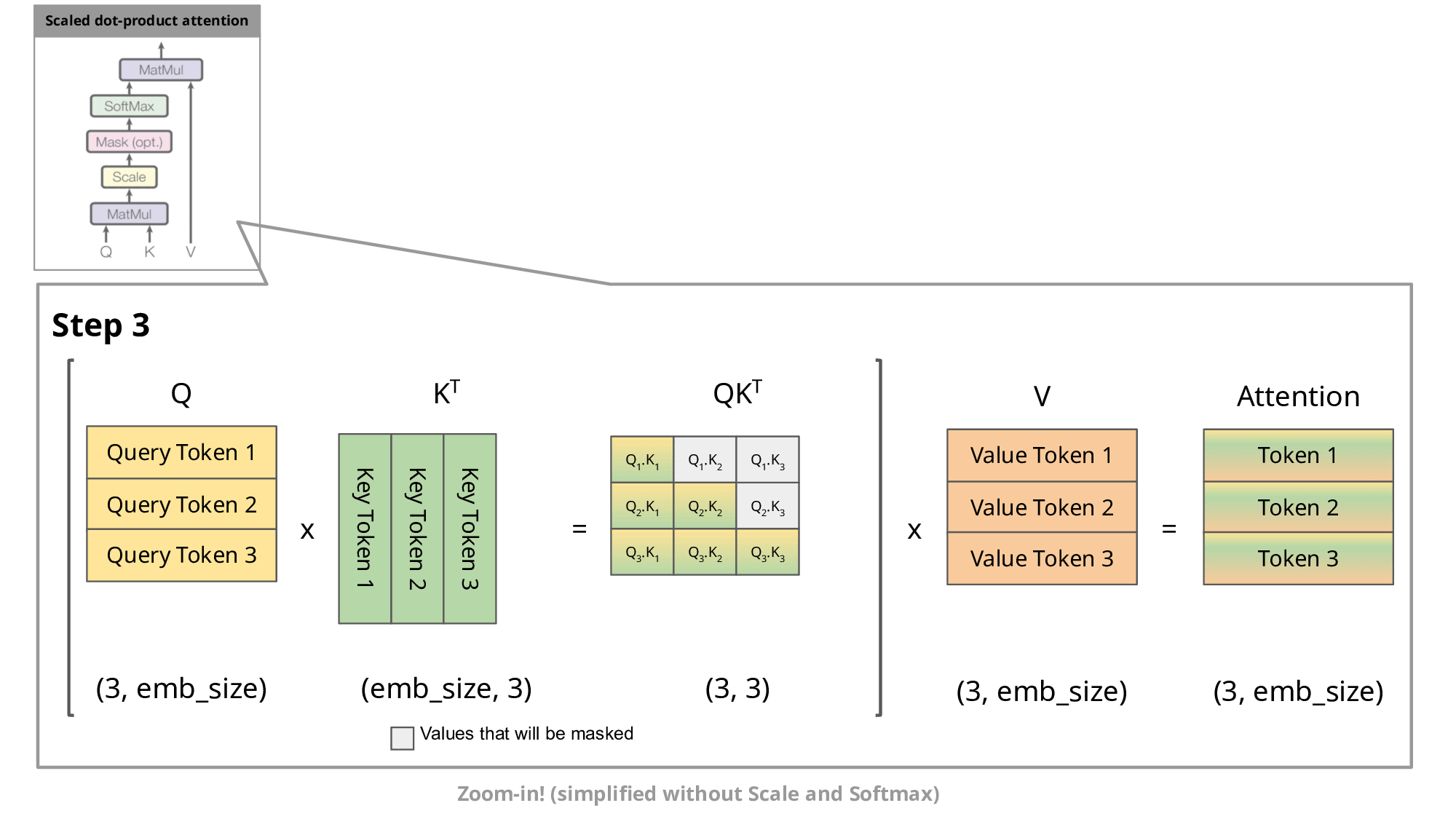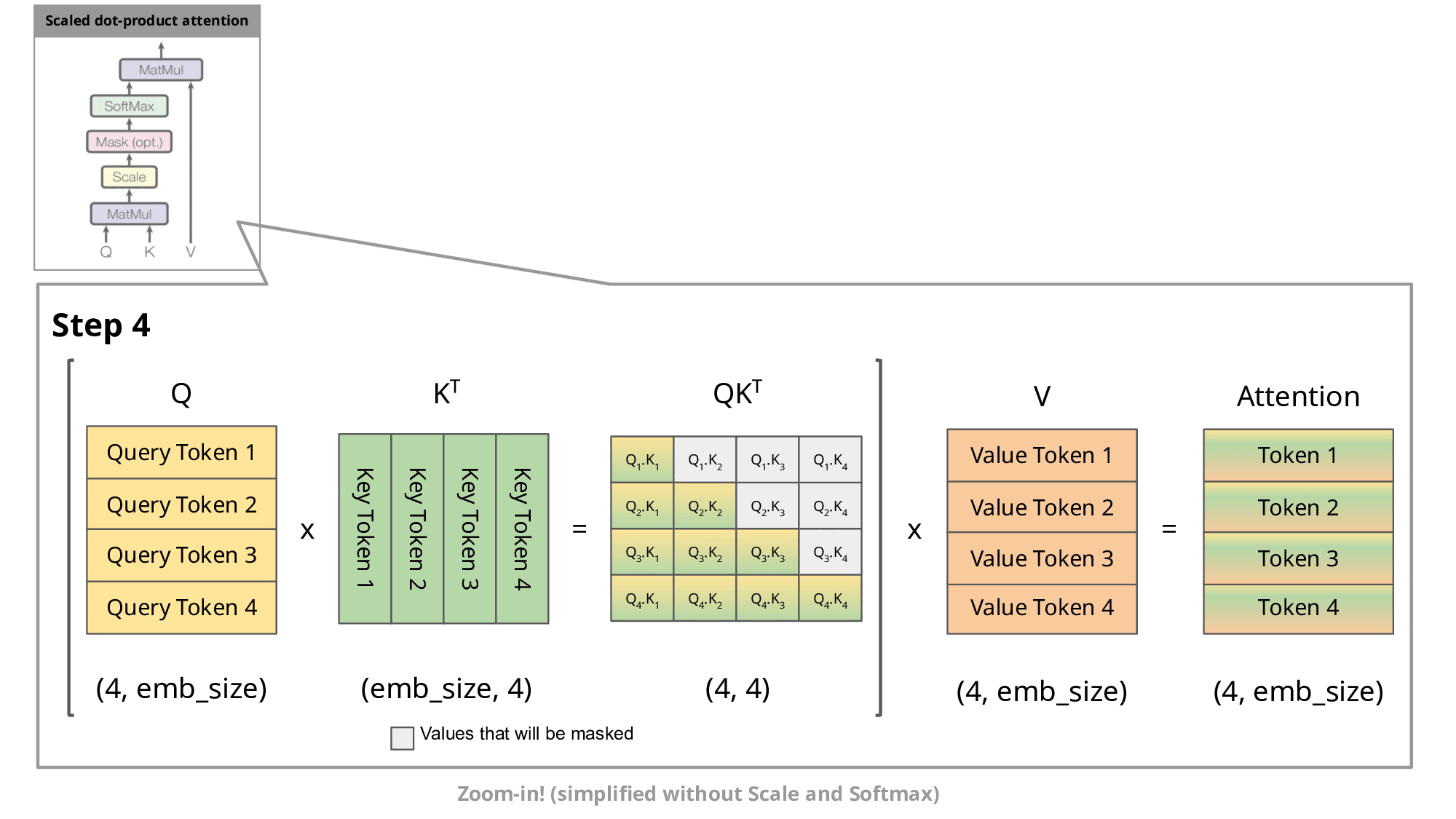
Fast-DLLM
こうした背景で出てきたのがFast-DLLMです。これは従来のKV‑cacheの概念をDLLMに取り込んだことと並列生成の品質を維持する工夫をしたことが大きな貢献です。
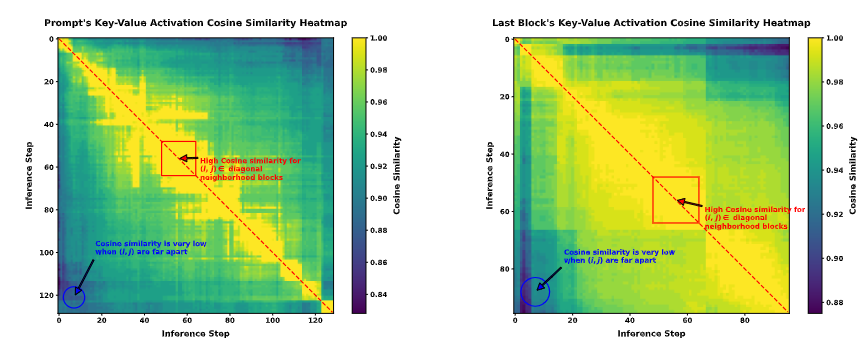
まずDLLM版のKV‑cacheとしてBlock-wise Approximate KV Cacheというものを提案しています。 これはプロンプトとそれに続く生成されるトークンシーケンスを「ブロック」に分割して扱います。なぜこのような分け方をするかというと、実験的にどうやら隣接するステップ間でKVの活性化するとこに類似性があるらしく、ブロックごとにmaskを予測などの逆方向拡散の手順を行う際、近似的なキャッシュを使っても問題ないという主張です。 論文中での根拠は以下の画像で示されています。 (簡単にまとめると、推論が進む中で、ごく近いステップの間では、モデルが内部で処理している情報(Key-Valueアクティベーション)がほとんど変わらないってこと)
予測ステップごとのヒートマップ。対角線上に強い類似性を持っているので過去の推論ステップで計算されたKey-Valueアクティベーションを保存し(キャッシュし)、それを隣接する将来のステップで再利用しても、モデルの性能に大きな悪影響を与えないことを視覚的に示している。
これによりブロックによる近似KVcache戦略を取れるようになったので以下の図のような効率化を測ります。
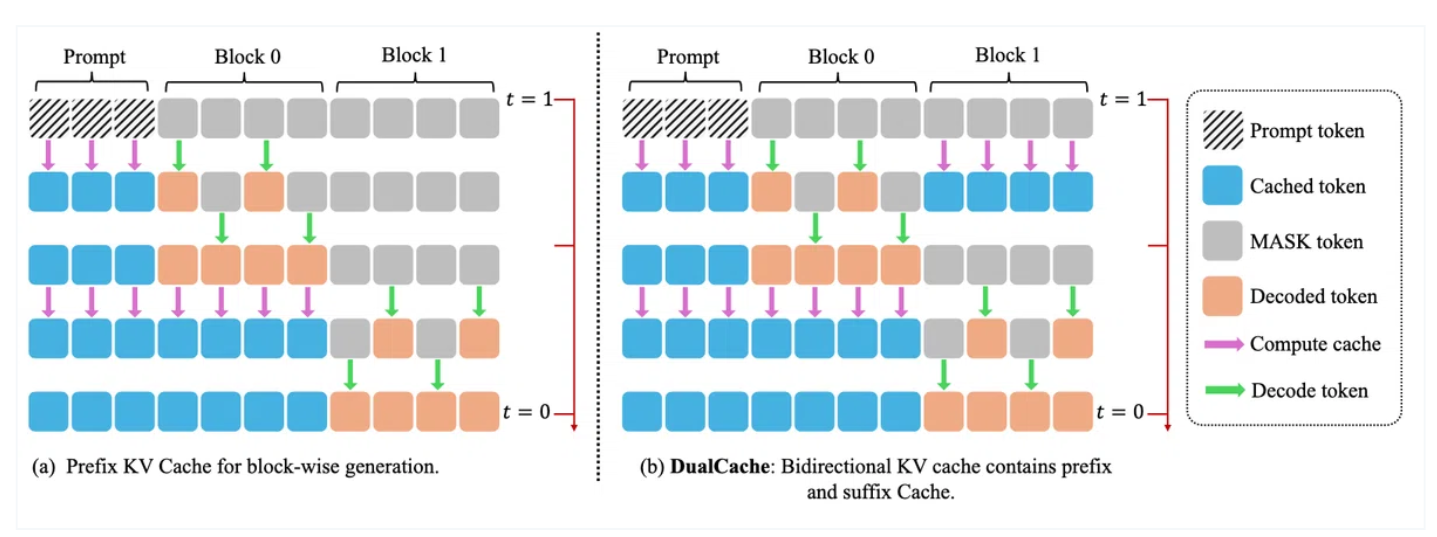
次に並列化の精度維持についてですがこれはConfidence‑Aware Parallel Decodingというものを提案しています。 従来はマスクされた複数トークンを一括で復元すると、**トークン間の依存関係を見落とす(conditional independence assumption)**ことで出力品質が落ちる場合があったのですが、信頼度が高いトークンだけを同時にunmaskし信頼度が低いのは後回しにすることで並列性と精度を活かす戦略としています。
最後に
DLLMは最初と最後で双方向で生成するわけだけどこれって最後の形決めちゃってるから固定長生成だけなんだろうな。つまり可変長生成に弱いという構造上の課題がありそう。 生成する際に最初にトークン数を決定し推論時に途中から伸ばそうとかはできないのだと思われます。 ちなみにMercuryがなんであんな柔軟なスケールで出せるかというと最初に長めの固定長を決めておいて、中間ステップで十分品質が整っていると判断したらそこで停止して出力するという戦略(Coarse‑to‑Fine生成+Early‑Exit(動的停止))をしているかららしい。